
Effort 等级完全拆解:ultrathink 的真相与推理深度的正确控制方式
「think / think hard / ultrathink」四段式映射在 Claude Code v2.1.72 之后已完全失效,当前版本用 Effort 等级系统(low/medium/high/xhigh/max)控制推理深度。本文完整拆解五个等级的实际行为差异、ultrathink 关键词的确切机制、设置优先级链路,以及升级模型后默认 effort 静默变更导致 token 超支的陷阱与应对方式。

「ultrathink 能给你最深的推理,think hard 其次,think 最基础。」
这句话在 2025 年是对的。在 2026 年,它已经过时了。
大量开发者仍在用「think」「think hard」「think harder」这些短语,期望它们触发不同深度的推理。但 Claude Code v2.1.72 之后,这些词组不再有任何系统级映射——它们只是普通的 prompt 文本,和「请认真考虑一下」没有区别。1
理解这个机制变迁,是把 Claude Code 推理深度用对的前提。
旧系统:固定 Token 预算(2025 年 v1 时代)
Anthropic 官方 Best Practices 文档曾明确写道:2
We recommend using the word 'think' to trigger extended thinking mode... These specific phrases are mapped directly to increasing levels of thinking budget: 'think' < 'think hard' < 'think harder' < 'ultrathink'.
这套机制基于固定 Token 预算:不同短语触发不同数量的思维 token 上限,
ultrathink 对应约 31,999 个 thinking tokens。控制思考深度 = 控制 token 预算。这套系统在 Claude Opus 4.6 及更早版本上运作。你说的词越「重」,模型拿到的思考额度越多,回答质量可见提升。
但这套系统在 2026 年初随着 Effort 系统上线而完全替换。
新系统:Effort 等级 + 自适应推理(2026 年)
当前 Claude Code(v2.1.72+)的推理深度控制完全基于 Effort 等级系统。3
核心机制是自适应推理(Adaptive Reasoning):模型不再依赖固定 token 预算,而是在每一步自行判断是否需要深度思考——简单问题直接回答,复杂问题才启动推理。Effort 等级控制的是模型「愿意花多少代价去思考」的整体倾向。
Opus 4.7 及更新版本全面迁移到自适应推理,固定 token 预算模式(
MAX_THINKING_TOKENS 环境变量)不再适用于这些模型。五个等级的实际行为
| 等级 | 触发方式 | 适用场景 | Token 消耗 |
|---|---|---|---|
low | /effort low 或 --effort low | 轻量子任务、批量 Subagent、简单查询 | 最低 |
medium | 默认值(部分场景) | 日常编码、文件操作、代码生成 | 中等 |
high | /effort high 或 ultrathink 关键词 | 架构决策、难以定位的 bug、深度分析 | 高 |
xhigh | /effort xhigh | 30 分钟以上的长时 Agent 任务、重型编码 | 显著高 |
max | /effort max(仅限当前 session) | 最高能力需求、逻辑密集任务 | 最高,无约束 |
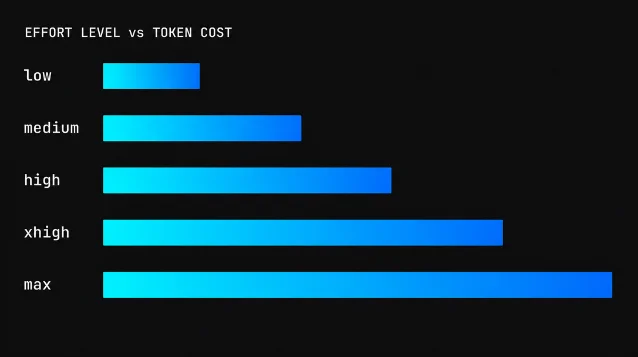
max 可达 low 的 2.7 倍以上 4Opus 4.8 和 Opus 4.7 支持全部五级;Opus 4.6 和 Sonnet 4.6 支持
low / medium / high / max 四级(无 xhigh)。max 的特殊性:session 限定,谨慎使用
max 提供无 token 约束的最高推理深度,但有两个重要限制:- 只对当前 session 生效,关闭 session 后失效。不能写入
settings.json的effortLevel字段(该字段只接受low/medium/high/xhigh) - 容易过度思考:官方文档明确标注「may show diminishing returns and is prone to overthinking」——对大多数编码任务,
xhigh的实际输出质量与max差别有限,但成本差距可能显著
社区对
max 的使用也趋于保守——Reddit r/ClaudeCode 上有专帖讨论 max 对普通编码任务的实际价值:Loading content card…
ultrathink:唯一保留的特殊关键词
在「think / think hard / think harder」全部失去系统级映射之后,只有
ultrathink 被官方重新收录为有效关键词。1它的确切行为:
- 在 prompt 中任意位置出现
ultrathink→ Claude Code 识别为特殊指令,对该 turn 触发higheffort 推理 - 仅影响当前 turn,完成后恢复 session 的常规 effort 设置
- 不会升级到
xhigh或max——无论你的当前 session effort 是什么,ultrathink的上限就是high - 如果 session 的 effort 已经是
high或以上,ultrathink实际无效果
用法示例:
ultrathink 这个认证流程的 token 刷新逻辑为什么会在并发请求下产生竞争条件?追踪 src/auth/ 里的完整调用链ultrathink 对比三种架构方案的优劣,我需要决定用 event sourcing 还是 CQRSultrathink vs 持久 effort 设置:选哪个?
| 场景 | 推荐方式 |
|---|---|
| 整个 session 都需要深度推理(如复杂重构) | /effort high 或 /effort xhigh,持久生效 |
| 大多数任务是日常编码,偶尔遇到难题 | 默认 effort + 特定 turn 用 ultrathink |
| 自动化脚本中某一步需要深度分析 | --effort high 启动参数,或在对应 turn 追加 ultrathink |
| Subagent 执行批量轻量任务 | 在 agent frontmatter 中设置 effort: low |
设置方式与优先级
Effort 等级有五种设置入口,优先级从高到低:5
CLAUDE_CODE_EFFORT_LEVEL 环境变量(最高优先级)
↓
/effort <level> 当前 session 设置
↓
settings.json 的 effortLevel 字段(持久化,接受 low/medium/high/xhigh)
↓
模型默认(Opus 4.8: high,Opus 4.7: xhigh,Opus 4.6 & Sonnet 4.6: high)实用细节:
/effort auto:把 session 的手动设置清除,回到模型默认值。注意:对 Opus 4.7 来说这会回到xhigh,不是降低 effort/effort在模型切换后不会自动重置,手动切了模型后记得重新确认 effort 设置ultracode(/effort ultracode)是另一个特殊选项:在xhigh推理的基础上额外触发动态工作流编排,让 Claude 自动规划多 Agent 协作方案。仅限当前 session,不写入settings.json
如何观察当前的 effort 状态
三个途径:
- 状态栏(如果你配置了 statusline):会实时显示当前 effort,如「with low effort」
/status命令:显示当前模型和账号信息,含 effort 等级/model选择器:左右方向键可以直接调整 effort 滑动条,同时完成模型和 effort 的确认
思考过程默认折叠。按
Ctrl+O 切换 verbose 模式后,推理内容以灰色斜体显示。如果想在交互 session 中看到完整的思维摘要而不只是折叠占位符,在 settings.json 里加 "showThinkingSummaries": true。注意:thinking tokens 和输出 token 按相同价格计费,即使折叠或不可见也照数扣费。6
实际运营建议
关于模型升级后的 effort 陷阱
从 Opus 4.6 升到 4.7 时,很多用户发现 5 小时 token 配额两小时就用完了。原因就是默认 effort 从
high 静默升级到了 xhigh。升级模型后第一件事应该是确认当前 effort 设置是否符合预期。成本敏感工作流的配置建议
// settings.json(持久化适中设置)
{
"effortLevel": "medium"
}然后在需要深度推理的具体 turn 追加
ultrathink,或临时 /effort high。Opus 4.7 的 medium 大致相当于 Opus 4.6 的 high——模型能力的提升在一定程度上补偿了 effort 降档的损失。7升级到 4.7 后 token 配额被默认
xhigh 快速消耗掉的问题,在 Reddit 引发了大量讨论:Loading content card…
Subagent 的 effort 控制
在 subagent 的 frontmatter 里可以独立设置
effort 字段,这会覆盖 session 级别的设置(但不覆盖环境变量)。批量执行轻量任务的子代理设置 effort: low 可以显著节省 token,把更高的 effort 预算留给主 Agent 处理复杂决策。---
tools:
- Read
effort: low
---固定 Token 预算的遗留路径
如果你的项目因历史原因仍在用 Opus 4.6 或 Sonnet 4.6,可以通过
CLAUDE_CODE_DISABLE_ADAPTIVE_THINKING=1 回退到固定 token 预算模式,此时 MAX_THINKING_TOKENS 环境变量重新生效。Opus 4.7 及以上版本不再支持此回退。8本文要点:「think / think hard / think harder」在当前版本不触发任何系统行为。
ultrathink 是唯一有效的 prompt 关键词,对应 high effort 的单次触发。持久推理深度控制通过 /effort 命令或 effortLevel 配置完成。升级模型后必须重新检查默认 effort,否则可能意外消耗更多 token。References
- 1Claude Code Model Config - Effort Level
- 2Claude Code Best Practices - Anthropic
- 3Claude Code Model Config - Adjust Effort Level
- 4I Tested All 5 Effort Levels of Claude Opus 4.7 - Towards AI
- 5Claude Code CLI Reference - effort flag
- 6Claude Code Extended Thinking Settings
- 7Claude Code effort levels community discussion
- 8Claude Code Adaptive Reasoning Settings
Add more perspectives or context around this Post.